
Siamo entusiasti di riportare Transform 2022 di persona il 19 luglio e intorno al 20-28 luglio. Unisciti ai leader dell’IA e dei dati per conversazioni approfondite ed entusiasmanti opportunità di networking. Registrati oggi!
OpenAI ha DALL-E 2 recentemente rilasciato, una versione più avanzata di DALL-E, un’ingegnosa intelligenza artificiale multimediale in grado di creare immagini basate esclusivamente su descrizioni testuali. DALL-E 2 fa questo utilizzando tecnologie avanzate di deep learning che migliorano la qualità e l’accuratezza delle immagini generate e forniscono funzionalità aggiuntive come la modifica di un’immagine esistente o la creazione di nuove versioni di essa.
Molti appassionati e ricercatori di intelligenza artificiale hanno twittato su quanto sia eccezionale il DALL-E 2 nel creare arte e immagini da parole sottili, ma in questo articolo vorrei esplorare una diversa applicazione di questo potente modello da testo a immagine: la creazione di set di dati risolvere Le maggiori sfide della visione artificiale.

Didascalia: immagine creata da DALL-E 2. “Un coniglio investigatore seduto su una panchina del parco e che legge un giornale in un luogo vittoriano”. fonte: Twitter
Difetti di visione artificiale
Le applicazioni AI della visione artificiale possono variare dal rilevamento di tumori benigni nelle scansioni TC all’abilitazione di auto a guida autonoma. Tuttavia, ciò che tutti hanno in comune è la necessità di dati abbondanti. Uno degli indicatori di prestazione più importanti di un algoritmo di deep learning è la dimensione del set di dati sottostante che è stato addestrato. Ad esempio, file set di dati JFTun set di dati interno di Google utilizzato per addestrare modelli di classificazione delle immagini, composto da 300 milioni di immagini e oltre 375 milioni di etichette.
Considera come funziona un modello di classificazione delle immagini: una rete neurale converte i colori di un pixel in un array di numeri che ne rappresentano le caratteristiche, noto anche come “incorporamento” di un input. Queste caratteristiche vengono quindi assegnate al livello di output, che contiene un punteggio di probabilità per ciascuna classe di immagini che il modello dovrebbe rilevare. Durante l’allenamento, la rete neurale cerca di apprendere le migliori rappresentazioni delle caratteristiche che distinguono tra le classi, ad esempio la caratteristica dell’orecchio appuntito di un doberman rispetto a un barboncino.
Idealmente, il modello di apprendimento automatico imparerà a generalizzare in diverse condizioni di illuminazione, angoli e ambienti di sfondo. Tuttavia, troppo spesso, i modelli di deep learning apprendono rappresentazioni errate. Ad esempio, una rete neurale potrebbe concludere che i pixel blu sono una caratteristica della classe “frisbee” perché tutto il frisbee che ha visto durante l’allenamento era sulla spiaggia.
Un modo promettente per risolvere tali carenze è aumentare le dimensioni del set di allenamento, ad esempio aggiungendo più immagini di frisbee con sfondi diversi. Tuttavia, questo processo può essere uno sforzo costoso e lungo.
Innanzitutto, dovrai raccogliere tutti i campioni richiesti, ad esempio effettuando ricerche online o scattando nuove foto. Successivamente, dovrai assicurarti che ogni capitolo abbia abbastanza etichette per evitare che il modulo sia personalizzato o non appropriato per alcuni. Infine, dovrai nominare ogni immagine, indicando quale corrisponde a quale categoria. in un mondo dove Più dati si traducono in un modello più performanteQuesti tre passaggi fungono da collo di bottiglia per ottenere prestazioni all’avanguardia.
Ma anche in questo caso, i modelli di visione artificiale possono essere facilmente ingannati, soprattutto se attaccati con esempi ostili. Indovina quale altro modo per mitigare gli attacchi ostili? Hai indovinato: dati più categorizzati, organizzati e diversificati.
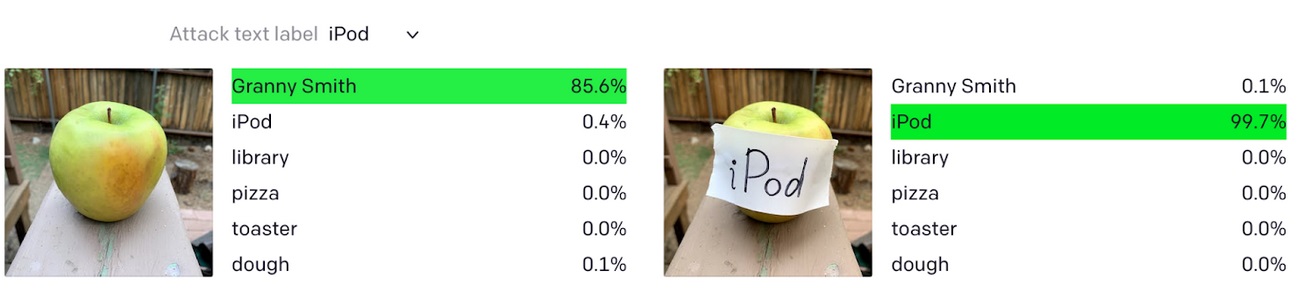
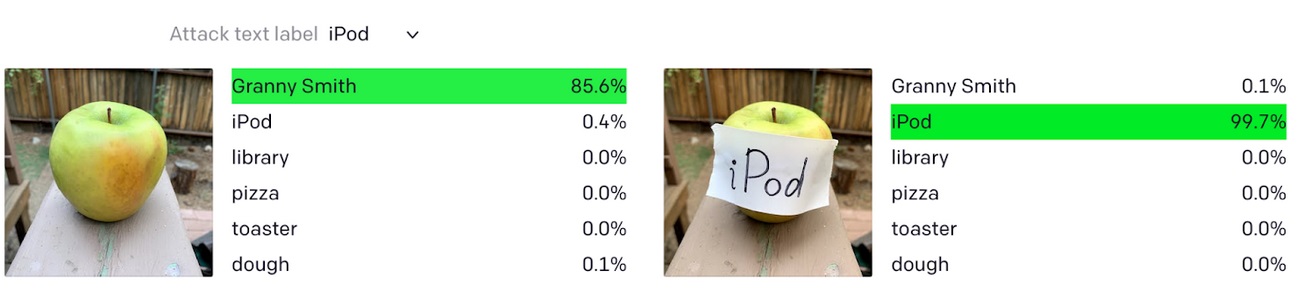
Didascalia: CLIP di OpenAI ha classificato erroneamente una mela come iPod a causa di un’etichetta di testo. fonte: aprire ai
Immettere DALL-E 2
Prendiamo l’esempio di un classificatore di razza canina e di una categoria per la quale è un po’ difficile trovare immagini: i dalmati. Possiamo usare DALL-E per risolvere il nostro problema di carenza di dati?
Prendi in considerazione l’applicazione delle seguenti tecnologie, tutte supportate da DALL-E 2:
- Usa la vaniglia. Inserisci il nome della classe come parte di un prompt di testo in DALL-E e aggiungi le immagini generate alle etichette di quella classe. Ad esempio, “Un cane dalmata nel parco sta inseguendo un uccello”.
- Ambienti e modelli diversi. Per migliorare la capacità del modello di generalizzare, utilizzare i prompt con ambienti diversi mantenendo la stessa classe. Ad esempio, “Un cane dalmata sulla spiaggia che insegue un uccello”. Lo stesso vale per lo stile dell’immagine creata, ad esempio “Un cane dalmata in giardino che insegue un uccello nello stile di un cartone animato”.
- Campioni scontati. Usa il nome della classe per creare un set di dati di esempi contraddittori. Ad esempio, “macchina dalmata”.
- differenze. Una delle nuove funzionalità di DALL-E è la possibilità di creare più variazioni dell’immagine in ingresso. Può anche scattare una seconda foto e unire le due unendo gli aspetti più importanti di ciascuna. Si può quindi scrivere uno script che alimenta tutte le immagini presenti nel set di dati per creare dozzine di variazioni per ogni classe.
- menpittura. DALL-E 2 può anche apportare modifiche realistiche alle immagini esistenti, aggiungendo e rimuovendo elementi, tenendo conto di ombre, riflessi e trame. Questa può essere una potente tecnica di aumento dei dati per addestrare ulteriormente e migliorare il modello di base.
Fatta eccezione per la generazione di più dati di formazione, il grande vantaggio di tutte le tecniche di cui sopra è che le immagini appena generate sono già etichettate, eliminando la necessità di una forza lavoro umana per l’etichettatura.
Sebbene le tecniche di generazione di immagini come Generative Adversarial Networks (GAN) siano in circolazione da qualche tempo, DALL-E 2 si distingue per le sue generazioni di 1024 x 1024 ad alta risoluzione, la sua natura multimediale di conversione da testo a immagine e la sua forte consistenza semantica, cioè una comprensione della relazione tra oggetti diversi in un’immagine specifica.
Automatizza la creazione di set di dati con GPT-3 + DALL-E
L’input DALL-E è un prompt di testo per l’immagine che vogliamo creare. Possiamo sfruttare GPT-3, il modello di generazione del testo, per generare decine di prompt di testo per ogni capitolo che verranno poi inseriti in DALL-E, che a sua volta genererà decine di immagini che verranno archiviate per ogni capitolo.
Ad esempio, possiamo creare prompt che includono diversi ambienti in cui vogliamo che DALL-E generi immagini di cani.
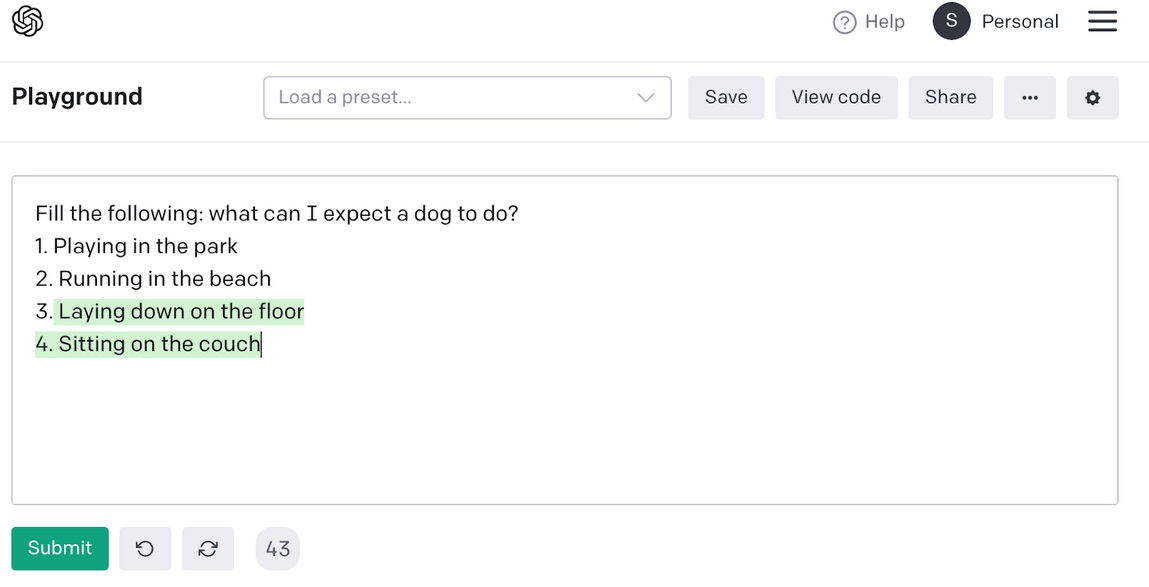
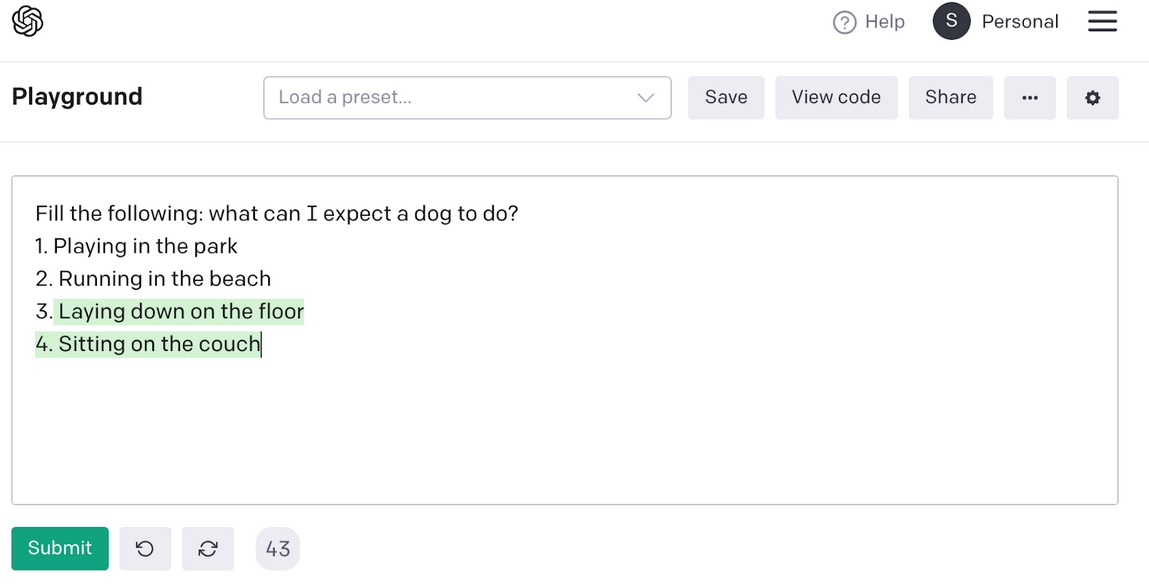
Didascalia: Un router creato da GPT-3 da utilizzare come input per DALL-E. Fonte: l’autore
Usando questo esempio, una frase simile a un modello come “a [class_name] [gpt3_generated_actions], “Possiamo dare da mangiare a DALL-E con il seguente messaggio: Un dalmata è sdraiato sul pavimento. Questo può essere ulteriormente migliorato ottimizzando GPT-3 per produrre sottotitoli di set di dati come quelli nell’esempio OpenAI Playground sopra.
Per aumentare la fiducia nei campioni appena aggiunti, è possibile impostare un limite di certezza per selezionare solo le generazioni che hanno superato una certa classificazione, poiché ogni immagine generata da un modello immagine-testo chiamato CLIP.
vincoli e ostacoli
Se non utilizzato con attenzione, DALL-E può generare immagini imprecise oa banda stretta, escludendo alcuni gruppi etnici o ignorando tratti che possono portare a pregiudizi. Un semplice esempio è un rilevatore di volti che è stato addestrato solo su ritratti di uomini. Inoltre, l’uso di immagini generate da DALL-E può comportare rischi significativi in campi specifici come la patologia o le auto a guida autonoma, dove il costo di un’immagine falsa negativa è proibitivo.
DALL-E 2 ha ancora alcune limitazioni, tra cui l’installazione. Basandosi su affermazioni che, ad esempio, presuppongono che la corretta posizione delle cose possa essere rischiosa.


Didascalia: DALL-E è ancora alle prese con alcune affermazioni. fonte: Twitter
I metodi per mitigare ciò includono il campionamento umano, in cui un esperto umano seleziona casualmente i campioni per la convalida. Per migliorare tale processo, si può adottare un approccio di apprendimento attivo in cui le immagini con la valutazione CLIP più bassa di un dato commento hanno la priorità per la revisione.
ultime parole
DALL-E 2 è un altro entusiasmante risultato di ricerca di OpenAI che apre le porte a nuovi tipi di applicazioni. Creazione di enormi set di dati per affrontare uno dei maggiori colli di bottiglia nella visione artificiale: i dati sono solo un esempio.
aprire ai segnali DALL-E verrà rilasciato la prossima estate, probabilmente in una versione graduale con pre-screening per gli utenti interessati. Coloro che non vedono l’ora, o che non possono pagare per questo servizio, possono armeggiare con alternative open source come il DALL-E Mini (interfaccia utenteE magazzino dello stadio).
Sebbene lo studio di fattibilità per molte applicazioni basate su DALL-E dipenderà dai prezzi e dalle politiche che OpenAI imposta per gli utenti della sua API, sono sicuri che tutti faranno un enorme balzo in avanti nella creazione di immagini.
Sahar Moore ha 13 anni di esperienza nell’ingegneria e nella gestione dei prodotti concentrandosi sui prodotti di intelligenza artificiale. Attualmente è Product Manager di Stripe e guida iniziative di dati strategici. In precedenza, ha fondato cartaun’API di document intelligence basata su GPT-3 ed è stato uno dei product manager fondatori di Zetold (Acq. di Deel), una società di software di contabilità AI B2B in cui ha costruito e ampliato il suo prodotto umano nel ciclo, e levitare, Piattaforma AutoML senza codice. Ha anche lavorato come direttore di ingegneria in start-up in fase iniziale e presso l’unità d’élite di intelligence israeliana, 8200.
decisori
Benvenuto nella comunità VentureBeat!
DataDecisionMakers è il luogo in cui gli esperti, inclusi i tecnici che lavorano sui dati, possono condividere idee e innovazioni relative ai dati.
Se vuoi leggere idee all’avanguardia e informazioni aggiornate, best practice e il futuro dei dati e della tecnologia dei dati, unisciti a noi su DataDecisionMakers.
Puoi anche pensare Contribuisci con un articolo Il tuo!

“Pluripremiato specialista televisivo. Appassionato di zombi. Impossibile scrivere con i guantoni da boxe. Pioniere di Bacon.”